Pain and gain of parsing large XML in Python
Overview
The task was straightforward: implement a simple stand-alone application which will parse a provided XML file containing Base64 encoded attachments and save them to the specified folder. The particular XML represents the structure of a dossier for a single medical product according to the specification. The resulting application was required to be cross-platform and have a simple user interface.
<?xml version="1.0" encoding="UTF-8"?>
<doc:DrugRegistrationDocDossierContentDetails xmlns:doc="urn:EEC:R:DrugRegistrationDocDossierContentDetails:v1.0.0" xmlns:bdt="urn:EEC:M:BaseDataTypes:v0.4.6" xmlns:ccdo="urn:EEC:M:ComplexDataObjects:v0.4.6" xmlns:csdo="urn:EEC:M:SimpleDataObjects:v0.4.6" xmlns:hccdo="urn:EEC:M:HC:ComplexDataObjects:v1.0.3" xmlns:hcsdo="urn:EEC:M:HC:SimpleDataObjects:v1.0.3" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:EEC:R:DrugRegistrationDocDossierContentDetails:v1.0.0 EEC_R_DrugRegistrationDocDossierContentDetails_v1.0.0.xsd">
<csdo:EDocCode>R.022</csdo:EDocCode>
<csdo:EDocId>fef37aff-70c1-441a-a7dc-4297d73b54ea</csdo:EDocId>
<csdo:EDocDateTime>2020-10-02T08:56:37</csdo:EDocDateTime>
<csdo:UnifiedCountryCode codeListId="P.CLS.019">AM</csdo:UnifiedCountryCode>
<hcsdo:RegistrationKindCode>01</hcsdo:RegistrationKindCode>
<hccdo:RegistrationDossierDocDetails>
<hcsdo:RegistrationFileIndicator>1</hcsdo:RegistrationFileIndicator>
<csdo:DocId>1.0.</csdo:DocId>
<csdo:DocName>Сопроводительное письмо к заявлению на выполнение процедур регистрации лекарственного препарата</csdo:DocName>
<hcsdo:DrugRegistrationDocCode>01001</hcsdo:DrugRegistrationDocCode>
<csdo:DocCreationDate>2020-10-02</csdo:DocCreationDate>
<hcsdo:DocCopyBinaryText mediaTypeCode="*.pdf">JVBERi0xLjc...</hcsdo:DocCopyBinaryText>
</hccdo:RegistrationDossierDocDetails>
...
</doc:DrugRegistrationDocDossierContentDetails>
Fig. 1. XML sample of medical product’s dossier
Fig. 1 presents a part of the original dossier containing a single Base64 encoded file and related information to it. The provided XML may contain more than one attachments enclosed in <hccdo:RegistrationDossierDocDetails> tags. The only aspect which distinguishes targeted dossier files is their size: they are way too large for in-memory processing. The size of such a dossier file may vary from ~100 MB to ~7 GB (the files I have encountered with). For this post I chose a 6.4 GB XML file.
First try
First step was naive parsing of an XML as a proof of concept and to get some insights. The initial application was a simple Python script which used ElementTree from its standard library for parsing. It constructs a document tree in memory and also has security implications. In order to mitigate those vulnerabilities, defusedxml was used in all implementations. It is a simple wrapper for stdlib XML parsers that prevents any potentially malicious operation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import os from base64 import b64decode from defusedxml.ElementTree import parse as parseXML def extract_dossier(xmlfile: str, output_dir: str): root = parseXML(xmlfile).getroot() docid_tag = '{urn:EEC:M:SimpleDataObjects:v0.4.6}DocId' docname_tag = '{urn:EEC:M:SimpleDataObjects:v0.4.6}DocName' docbintext_tag = '{urn:EEC:M:HC:SimpleDataObjects:v1.0.3}DocCopyBinaryText' for node in root.findall( '{urn:EEC:M:HC:ComplexDataObjects:v1.0.3}' 'RegistrationDossierDocDetails' ): # parse document details doc_name = node.find(docname_tag).text binnode = node.find(docbintext_tag) ext = binnode.attrib.get('mediaTypeCode', '*.pdf').split('.')[-1] if doc_name.endswith(ext): filename = doc_name else: filename = f'{doc_name[:50]}.{ext}' # save found document with open(os.path.join(output_dir, filename), 'wb') as fd: fd.write(b64decode(binnode.text)) |
Fig. 2. Source code for first attempt
One of the main requirements for the application alongside performance was low memory usage, otherwise the users possessing systems with small amounts of RAM won’t be able to run file extraction processes. Thus the script needed to be evaluated for memory usage. For that reason it was profiled using memory_profiler. It is an easy to use pure Python module with support for line-by-line analysis of memory consumption.
Line Mem usage Increment Occurrences Line Contents
=============================================================
9 18.8 MiB 18.8 MiB 1 @profile
10 def extract_dossier(xmlfile: str, output_dir: str):
11 6516.5 MiB 6497.7 MiB 1 root = parseXML(xmlfile).getroot()
12 6516.5 MiB 0.0 MiB 1 docid_tag = '{urn:EEC:M:SimpleDataObjects:v0.4.6}DocId'
13
14 6516.5 MiB 0.0 MiB 1 docname_tag = '{urn:EEC:M:SimpleDataObjects:v0.4.6}DocName'
15 6516.5 MiB 0.0 MiB 1 docbintext_tag = '{urn:EEC:M:HC:SimpleDataObjects:v1.0.3}DocCopyBinaryText'
16
17 7635.8 MiB -52.8 MiB 576 for node in root.findall(
18 6516.5 MiB 0.0 MiB 1 '{urn:EEC:M:HC:ComplexDataObjects:v1.0.3}'
19 'RegistrationDossierDocDetails'
20 ):
21 # parse document details
22 7635.8 MiB -52.8 MiB 574 doc_name = node.find(docname_tag).text
23 7635.8 MiB -52.8 MiB 574 binnode = node.find(docbintext_tag)
24 7635.8 MiB -52.8 MiB 574 ext = binnode.attrib.get('mediaTypeCode', '*.pdf').split('.')[-1]
25
26 7635.8 MiB -52.8 MiB 574 if doc_name.endswith(ext):
27 7635.8 MiB -52.8 MiB 574 filename = doc_name
28 else:
29 filename = f'{doc_name[:50]}.{ext}'
30
31 # save found document
32 7635.8 MiB -105.6 MiB 1148 with open(os.path.join(output_dir, filename), 'wb') as fd:
33 7635.8 MiB 1067.8 MiB 574 fd.write(b64decode(binnode.text))
Fig. 3. Memory profile report
This report contains a memory profile output. It can be seen from the report, that our script loads the whole content of the XML file and builds a tree in memory. At the very first line of the “extract_dossier” function XML is parsed and causes high memory consumption. Thus memory usage picks and the dossier processing may not be executed on the hardware with lower RAM.
The memory_profiler has nice plotting functionality, so we can clearly see the memory usage of our application.
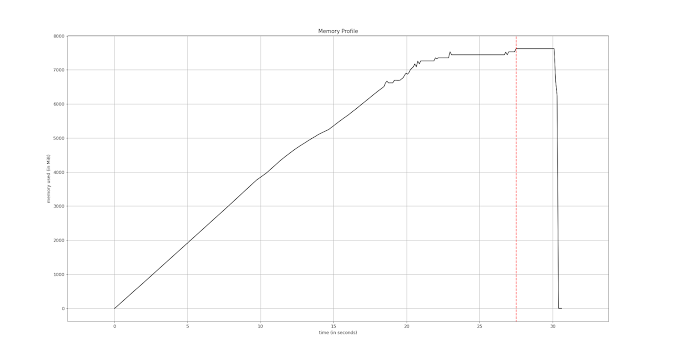
Fig.4. Plot of “memory_profiler” report
It can be clearly seen from both Fig.3 and Fig.4, that memory usage is too high, which is not acceptable. Although by utilizing a memory profiler we have been able to identify the problem.
Second try
For the second try iterparse from ElementTree API was used for incremental parsing. It still blocks on reading data, but uses far less memory. The iterparse function creates an iterator object which emits an event and a single element on each iteration. The reported events are configurable. The resulting iterative XML parsing code looked like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | import os from base64 import b64decode from defusedxml.ElementTree import iterpar def extract_dossier(xmlfile: str, output_dir: str): dossier_details_tag = ( '{urn:EEC:M:HC:ComplexDataObjects:v1.0.3}' 'RegistrationDossierDocDetails' ) docname_tag = '{urn:EEC:M:SimpleDataObjects:v0.4.6}DocName' docbintext_tag = '{urn:EEC:M:HC:SimpleDataObjects:v1.0.3}DocCopyBinaryText' for event, elem in iterparse(xmlfile): if elem.tag != dossier_details_tag: continue # parse document details doc_name = elem.find(docname_tag).text binnode = elem.find(docbintext_tag) ext = binnode.attrib.get('mediaTypeCode', '*.pdf').split('.')[-1] if doc_name.endswith(ext): filename = doc_name else: filename = f'{doc_name[:50]}.{ext}' # save found document with open(os.path.join(output_dir, filename), 'wb') as fd: fd.write(b64decode(binnode.text)) elem.clear() |
Fig. 5. Source code for incremental XML parsing
The same profiling technique was applied to the source code in fig.5 in order to determine memory usage.
Line Mem usage Increment Occurrences Line Contents
=============================================================
62 18.8 MiB 18.8 MiB 1 @profile
63 def extract_dossier(xmlfile: str, output_dir: str):
64 18.8 MiB 0.0 MiB 1 dossier_details_tag = (
65 18.8 MiB 0.0 MiB 1 '{urn:EEC:M:HC:ComplexDataObjects:v1.0.3}'
66 'RegistrationDossierDocDetails'
67 )
68 18.8 MiB 0.0 MiB 1 docname_tag = '{urn:EEC:M:SimpleDataObjects:v0.4.6}DocName'
69 18.8 MiB 0.0 MiB 1 docbintext_tag = '{urn:EEC:M:HC:SimpleDataObjects:v1.0.3}DocCopyBinaryText'
70 208.1 MiB -656961.3 MiB 5238 for event, elem in iterparse(xmlfile):
71 208.1 MiB -657640.8 MiB 5237 if elem.tag != dossier_details_tag:
72 208.1 MiB -586844.0 MiB 4663 continue
73
74 # parse document details
75 208.1 MiB -70796.8 MiB 574 doc_name = elem.find(docname_tag).text
76 125.5 MiB -76651.0 MiB 574 binnode = elem.find(docbintext_tag)
77 125.5 MiB -32512.2 MiB 574 ext = binnode.attrib.get('mediaTypeCode', '*.pdf').split('.')[-1]
78
79 125.5 MiB -32512.2 MiB 574 if doc_name.endswith(ext):
80 125.5 MiB -32512.2 MiB 574 filename = doc_name
81 else:
82 filename = f'{doc_name[:50]}.{ext}'
83
84 # save found document
85 208.1 MiB -105794.5 MiB 1148 with open(os.path.join(output_dir, filename), 'wb') as fd:
86 208.1 MiB -70421.5 MiB 574 fd.write(b64decode(binnode.text))
87
88 208.1 MiB -72074.6 MiB 574 elem.clear()
Fig. 6. Memory profile report for incremental XML parsing
As it can be determined from memory profile report from fig. 6, memory allocated during each iteration is released, thus reducing total memory consumption. The memory for each event and element is allocated at the beginning of each iteration (fig. 6 line 70) and freed at the end of the for loop’s body (fig. 6 line 88).
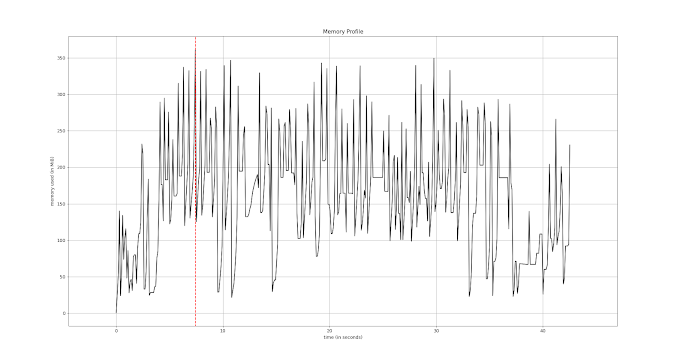
Fig. 7. Memory profile chart for incremental XML parsing
Fig.7 better illustrates memory allocations and releases, proving that each iteration uses only the amount of memory needed for parsing a single node and Base64 encoded file. The most important part is removing processed elements from the memory. For that particular operation elem.clear() is called after necessary operations are performed inside the loop. During the implementation of incremental parsing (fig. 5) the element removal part was skipped at first causing the same memory usage as the first implementation (fig. 2).
The same application was also implemented using the lxml library. It also provides incremental XML parsing capabilities with a very similar API.
from lxml.etree import iterparse
...
for event, elem in iterparse(open(xmlfile, 'rb'), huge_tree=True):
...
Fig. 8. Incremental parsing XML with lxml
As it can be determined from fig. 8 that lxml’s iterparse function takes binary stream as an input. Also it requires explicit specification for huge text nodes present in the XML file to be able to parse it. Rather than the import and for loop changes the code from fig.5 is unmodified. Though the lxml library is considered to be faster and more memory efficient than its counterpart ElementTree from Python’s standard library, for this particular task it didn’t provide significant benefits. The memory usage was comparable. So it was decided not to use an external dependency.
Conclusion
The pain: Parsing XML is hard. Parsing XML with hundreds of Base64 encoded files is harder. One can face different limitations as memory consumption or total parsing time during development of such applications. Of course there are different parsing libraries both in standard library and as third party dependencies and choosing one or other isn’t a simple task itself.
The gain: Using memory profiling (or profiling in general) and understanding internal data structures of the standard and non-standard libraries are essential skills, which are by the way language and platform independent, and worth investing into. In some cases profiling may be the only option to understand the behavior of the application or even a simple script.
Final result: As the medicine dossier extraction is required by one of our clients, they needed a simple tool for performing that task. Thus a small cross platform desktop application was developed, which utilized described technique of large XML processing.
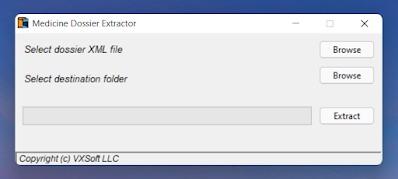
Fig. 9. Medicine dossier extraction application
The application (fig. 9) was able to process 6.4GB XML file with maximum memory usage of 208.1MB.