Compiling docx templates with python-docx
Overview
Nearly in every solution related to the document workflow we are forced to deal with several different document formats. From the development point of view. the best document formats to deal with are csv/xlsx and pdf, for report and receipt/certificate generation respectively. But life is not that easy as we would like it to be, so we need to deal with docx documents as well, and by saying “dealing with” I mean creating, generating, parsing, modifying and using them as template for document generation.
Using docx as document template
As our language and environment of choice is Python we have several good enough libraries for working with each document format mentioned above. Python’s standard csv library covers all needs related to csv reports or data extraction tasks. For pdf document generation we are using wkhtmltopdf open source tool and xlsx documents are handled with the help of XlsxWriter and openpyxl libraries. Now there’s no issue with the docx document libraries as well (and we will discuss python-docx in this article), unless you’re using them as a template for document generation. Here’s the simple diagram for general usage of docx templates in our solutions.
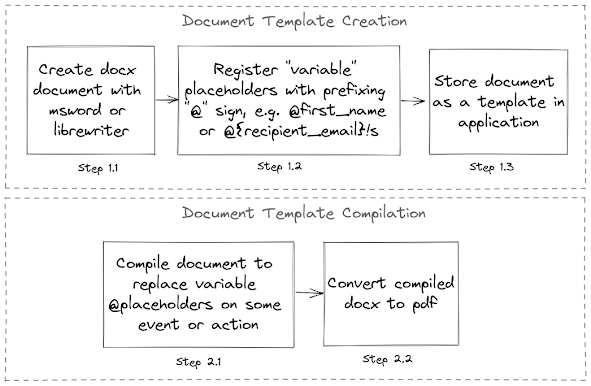
Fig.1. DOCX typical usage in our applications
How it was done and what was missing
Document template compilation (Step 2.1 on the Fig.1) was implemented via our template library provided by the wheezy.web framework that we are building our web application on. It's not much different from Jinja2 or Django templates so you need to have valid HTML/XML as a source. To be able to compile document as XML/HTML we were extracting "document.xml" file from docx archive as shown in the code snippet below.
1 2 | with zipfile.ZipFile(io.BytesIO(base64.b64decode(docx_document))) as archive: template = archive.read('word/document.xml').decode('utf-8') |
Fig. 2. docx archive unpacking
After extracting document.xml file we were passing it and variable dictionary to the template compilation engine and getting compiled xml file on the output. To get compiled docx we were pulling back together zip archive already with the replaced original document.xml.
There are couple of disadvantages in this routine.
It is complex.
You need to know internal structure of the docx archive.
You can only compile text variables into the docx.
But, hey, it’s working for us for 5 years on ~150 installations.
The biggest issue was the 3rd point mentioned above. There was a requirement to place not only text variables, but photos and tables as well, which is impossible in case of document compilation with HTML template engine.
dompx - the docx domper
After some research on docx document manipulation libraries for python, we have decided to give python-docx library a try. It is well documented, the code structure and style is very clean, so we were able to find answers to our questions in a very short period.We have decided to write a small document compilation engine to replace our existing one and on our way we had one very bold requirement: existing document templates should seamlessly work on the new engine and no-one should even notice that something has changed under the hood.With the help of python-docx we have understood the structure of the docx documents (paragraphs, runs, elements, etc.) and parsing document for it’s smallest components became a piece of cake…or more accurately it became semi-recursive generator function presented on Fig 3.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | def paragraphs(document: Document) -> Paragraph: """Paragraph generator for the document Parameters ---------- document : Document Yields ------ Paragraph """ # first are document level paragaphs for paragraph in document.paragraphs: yield paragraph # we have also paragraph hidden in the document level tables yield from table_paragraphs(document.tables) # header level paragraphs goes here header = document.sections[0].header for paragraph in header.paragraphs: yield paragraph # header level table paragraphs goes here yield from table_paragraphs(header.tables) # footer level paragraphs goes here footer = document.sections[0].footer for paragraph in footer.paragraphs: yield paragraph # footer level table paragraphs goes here yield from table_paragraphs(footer.tables) def table_paragraphs(tables: Iterable) -> Paragraph: """Extracting table-level paragraphs which are hidden in the table cells Parameters ---------- tables : Iterable Yields ------ Paragraph """ for table in tables: for col in table.columns: for cell in col.cells: for paragraph in cell.paragraphs: yield paragraph # but wait, there's more! what about tables hidden in the # table cells? yield from table_paragraphs(cell.tables) |
Fig. 3. Iterating over document paragraphs
So the next major task was variable placeholder detection [find better word] and replacement with the text, image or a table defined as a variable modifier/filters. General syntax for variable placeholders can be summarized as @{variable_name}!modifier expression. For detecting such placeholders in the docx paragraphs (or in the runs) we used following regular expression (Fig 4).
1 2 3 4 | # regular expression for extracting wheezy.template like variables and # expressions from the docx document: ex. @{data['key']}!ss token = re.compile(r'(@{?[\w\.\[\]\'\"\(\)]+}?)(![a-z]+)?') |
Fig. 4. Super-puper regular expression
The next step is replacing variable_name with it’s according value. Note that variable name actually can be any valid Python expression really, like data[‘first_name’] or data.get(‘first_name’, {}).get(‘en’, ’’) or alike. To compile these expressions we used Python’s eval method against the predefined dataset (Fig 5).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | def compile_expr(expr: str, data: dict) -> str: """Compiling expression matched by regexp against data Parameters ---------- expr : str data : dict Returns ------- str """ try: # we need to remove @, {, } symbols to work with pure python expression val = eval(expr[1:].strip('{}'), {}, data) # nosec except Exception as ex: throw(_("Can't generate file due to not well formed template: [{ex}]"), params={'ex': str(ex)}) return val |
Fig. 5. Evaluating Python expression against data
To support various data types, like images or tables, we implemented various docx injection methods and bound them with a modifier used in placeholder definition. Hence the placeholder for injecting image into the document will be something like this: @{profile_picture}!img. Variable “profile_picture” should contain the path of the image and !img modifier will define the method for handling image injection. Similar to this !tbl modifier will direct data to the table injection method. On Fig 6 are presented injection methods described above.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | def img(doc: Document, run: Run, expr: str, mod: str, data: dict): """Embbed image into the document Parameters ---------- doc : Document run : Run expr : str mod : str data : dict """ # in case of images we don't need expression in the run, hence replacing it # with the empty string run.text = run.text.replace(f'{expr}{mod}', '') # image "value" here should be a path of the image if picture := compile_expr(expr, data): path, width, height = None, None, None if isinstance(picture, str): path = picture elif isinstance(picture, tuple): path, width, height = picture else: return run.add_picture( path, width=(width and Mm(width)), height=(height and Mm(height)) ) def tbl(doc: Document, run: Run, expr: str, mod: str, data: dict): """Embbed table into the document Parameters ---------- doc : Document run : Run expr : str mod : str data : dict """ # in case of table we don't need expression in the run, hence replacing it # with the empty string run.text = run.text.replace(f'{expr}{mod}', '') if matrix := compile_expr(expr, data): # as for now we are supporting strict structured matrix like data, e.g. # list of lists if not isinstance(matrix, list) and not isinstance(matrix[0], list): return # create a table in document with matrix dimensions table = doc.add_table(len(matrix), len(matrix[0])) table.style = 'Table Grid' # and populate the table with the matrix values for ridx, row in enumerate(matrix): for cidx, cell in enumerate(row): table.cell(ridx, cidx).text = str(cell) run.element.addnext(table._tbl) |
Fig. 6. Image and table compilers
Summary
By using python-docx we have simplified our solution and in the same time we have hugely improved our knowledge and capabilities of docx manipulations. Also we have created framework agnostic solution for dealing with docx templates.